
In today’s world, everybody can make Deepfakes by recording a voice sample. So let’s understand what this new method can do by example. Let’s watch the below short clip of a speech, and make sure to pay attention to the fact that the louder voice is the English translator. If you pay attention, you can hear the chancellor’s original voice in the background too. So what is the problem here? Honestly, there is no problem here, this is just the way the speech was recorded.
But can we recreate this video in a way that the chancellor’s lips would be synced not to her own voice, but to the voice of the English interpreter? This would give an impression as if the speech was given in English, and the video content would follow what we hear.
It sounds fictional, doesn’t it? But this method can make it real and perform better than the state of the art technique from last year that attempts to perform this. The remnants of the previous speech are still there, but the footage is much, much more convincing.
It can do way more than this, many of us are sitting at home, learning new stuff from videos, but the vast majority of these were recorded in only English. What if we could redub famous lectures into many other languages? Look at the below video. Any lecture could be available in any language and look as if they were originally recorded in foreign languages – as long as someone like a dubbing artist says the words. That too can possibly be automated through speech synthesis these days.
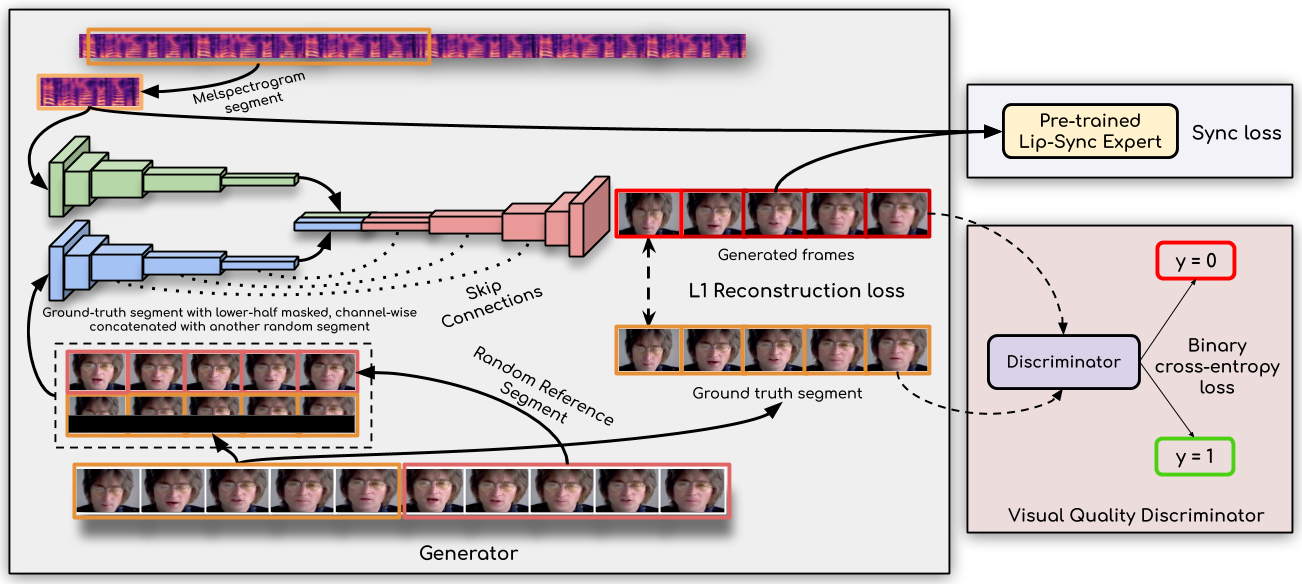
This approach generates accurate lip-sync by learning from an “already well-trained lip-sync expert”. Unlike previous works that employ only a reconstruction loss or train a discriminator in a GAN setup, the authors use a pre-trained discriminator that is already quite accurate at detecting lip-sync errors. They also employ a visual quality discriminator to improve the visual quality along with the sync accuracy. So the 2 main components are a pre-trained lip-sync expert and the discriminator.
The authors jointly improve the quality of the lip-syncing and the visual quality of the video. These two modules curate the results offered by the main generator neural network and reject solutions that don’t have enough detail or don’t match the speech that we hear, and thereby they steer it towards much higher-quality solutions.
These are useful Deepfakes that can potentially help people around the world to study and improve themselves, reduce communication barriers, etc
References
- A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild: https://arxiv.org/abs/2008.10010
Author
Shubham Bindal
