
In the last part, we discussed what ensembling learning in ML is and how it is useful. We also discussed one ensemble learning technique – Bagging – and algorithms that are based on it i.e. Bagging meta-estimator and Random Forest. In this part, we will discuss another ensemble learning technique, which is known as Boosting, and some machine learning algorithms that are based on Boosting.
Boosting
In Bagging, to predict the output we combine the results that we get from different models, which we trained on different subsets of data. But what if a data point is incorrectly predicted by the first model, and then by the next model, and maybe by all models? Then will combining the predictions provide better results?
The answer is simple: No. So to handle such situations we use another ensembling technique, which is Boosting. Boosting is an ensemble learning technique that uses a group of machine learning algorithms to convert weak learning models to strong learning models so as to extend the accuracy of the model. It is actually a very effective method to increase the efficiency of your model.
Boosting is implemented by combining several weak learners into a single strong learner. Here are the typical steps to do it:
- A subset is made from the first dataset.
- Initially, all data points are given equal weights.
- A base model is created on this subset.
- This base model is used to make predictions on the whole dataset.
- Errors are calculated using the actual values and predicted values of the base model.
- The observations which are incorrectly predicted are given higher weights (not equal weights) so that another model can focus more on these observations which were not correctly treated by the previous model.
- Then another model is created and predictions are made on the dataset.
- In this way, multiple models are created, each model correcting the errors of the previous model.
- The final model (which is a strong learner) is the weighted mean of all the models (which are weak learners)
Boosting algorithms are often supported on convex or even on non-convex optimization algorithms. Convex algorithms like AdaBoost and LogitBoost are often defeated by random noise as they can’t learn basic and learnable combinations of weak hypotheses, while boosting algorithms that support non-convex optimization, like BrownBoost, can learn from the noisy datasets.
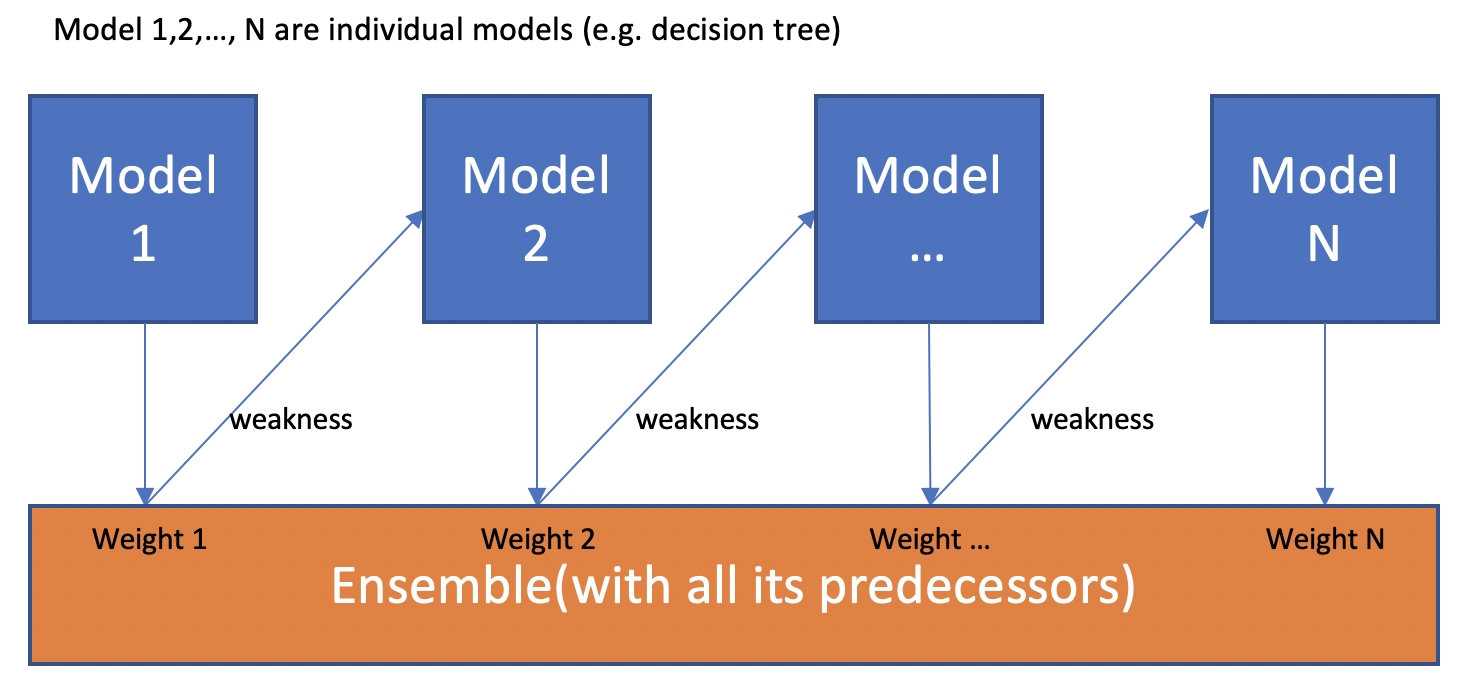
Some of the most popular boosting based ML algorithms are AdaBoost (Adaptive Boosting), Gradient Tree Boosting (Gradient Boosting), XGBoost, etc. We discuss AdaBoost and Gradient Boosting.
Some Boosting based ML algorithms
AdaBoost

Box 1: You can see that we’ve assigned equal weights to every data observation and applied a decision stump to classify them as a square or a circle. The decision stump has generated a vertical line on the left side to classify the data points. We see that this vertical line has incorrectly predicted three squares as circles. In such a case, we’ll assign higher weights to these three squares and apply another decision stump.
Box 2: Here, you can see that the size of three incorrectly predicted squares is bigger as compared to the rest of the data points. In this case, the second decision stump will try to predict them correctly. Now, a vertical line on the right side of this box has classified three misclassified squares correctly. But again, it has caused misclassification errors. This time with three circles. Again, we will assign a higher weight to three circles and apply another decision stump.
Box 3: Here, three circles are given higher weights. A decision stump is applied to predict these misclassified observations correctly. This time a horizontal line is generated to classify squares and circles based on the higher weight of misclassified observation.
Box 4: Here, we’ve combined all decision stumps to make a robust prediction having complex rules as compared to the individual weak learners. You can see that this algorithm has classified these observations quite well as compared to any single weak learner.
It fits a sequence of weak learners on different weighted training data. It starts by predicting the first data set and provides equal weight to every observation. If the prediction is wrong using the primary learner, then it gives higher weight to observation which has been predicted incorrectly. Being an iterative process, it continues to add new learners until a limit is reached within the number of models or accuracy.
Gradient Boosting
In gradient boosting, it trains many models sequentially. Each new model gradually minimizes the loss function of the entire system using the Gradient Descent method.
y = ax + b + e
Here e is the error term. The training procedure consecutively fits new models to supply a more accurate estimate of the response variable.
The idea behind this is to construct new base learners which may be maximally correlated with the negative gradient of the loss function, which is related to the whole ensemble.
Let’s see an example. Suppose you have a regressive model which predicts 5 for a test case whose actual outcome is 2. So in this case, if we know the error, we can fine-tune the prediction by subtracting the error, which is 3, from the predicted value of 5 and obtain an accurately predicted value of 2. So the question now is, “How do we know the error which is made by our model for any given input?”
For this task, we can train a new predictor to predict the errors made by the original model.
Now, for any given predictive model, we can improve its accuracy by first training a new predictor to predict its current errors and then forming a new improved model whose output is the fine-tuned version of the original prediction. Now the improved model, which requires the outputs of both the original predictor and the error predictor, is now considered an ensemble of the two predictors. In gradient boosting, this is repeated an arbitrary number of times to improve the model’s accuracy and this repeated process forms the basis of gradient boosting.
This was a quick introduction to the Boosting ensembling technique. In the next part, we will explore the Stacking ensembling technique, how it works, how it is different from bagging and boosting, ML algorithms that are based on it, and its advantages. See you in the next part of this series!! 🙂
Author
Shubham Bindal
