
In this short article, we will look at the state of egocentric videoconferencing. Now, this doesn’t mean that only we get to speak during a meeting, it means that we are wearing a camera, which looks like the Input (in below video). The goal is to use a learning algorithm to synthesize this frontal view of us, you can see the recorded reference footage, which is the reality (Ground Truth). This real footage (Ground Truth) would need to be somehow synthesized by the algorithm, the predicted one from this algorithm (Predicted). If we could pull that off, we could add a low-cost egocentric camera to smart glasses and it could pretend to see us from the front, which would be amazing for hands-free videoconferencing.
There are four major problems to overcome here:
- The camera lens is very close to us, which means that it doesn’t see the entirety of the face, and that is extremely challenging
- A ton of distortion is in the images, or in other words, things don’t look like they look in reality and the system needs to account for that too
- It would also need to take into account the current expression, gaze, blinking, and more
- The output needs to be photorealistic. Remember, we don’t just need one image but a continuously moving video output
In the above video, we can see that this work is giving us a nearly perfect reconstruction of the remainder of the human face. They employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. This approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods.
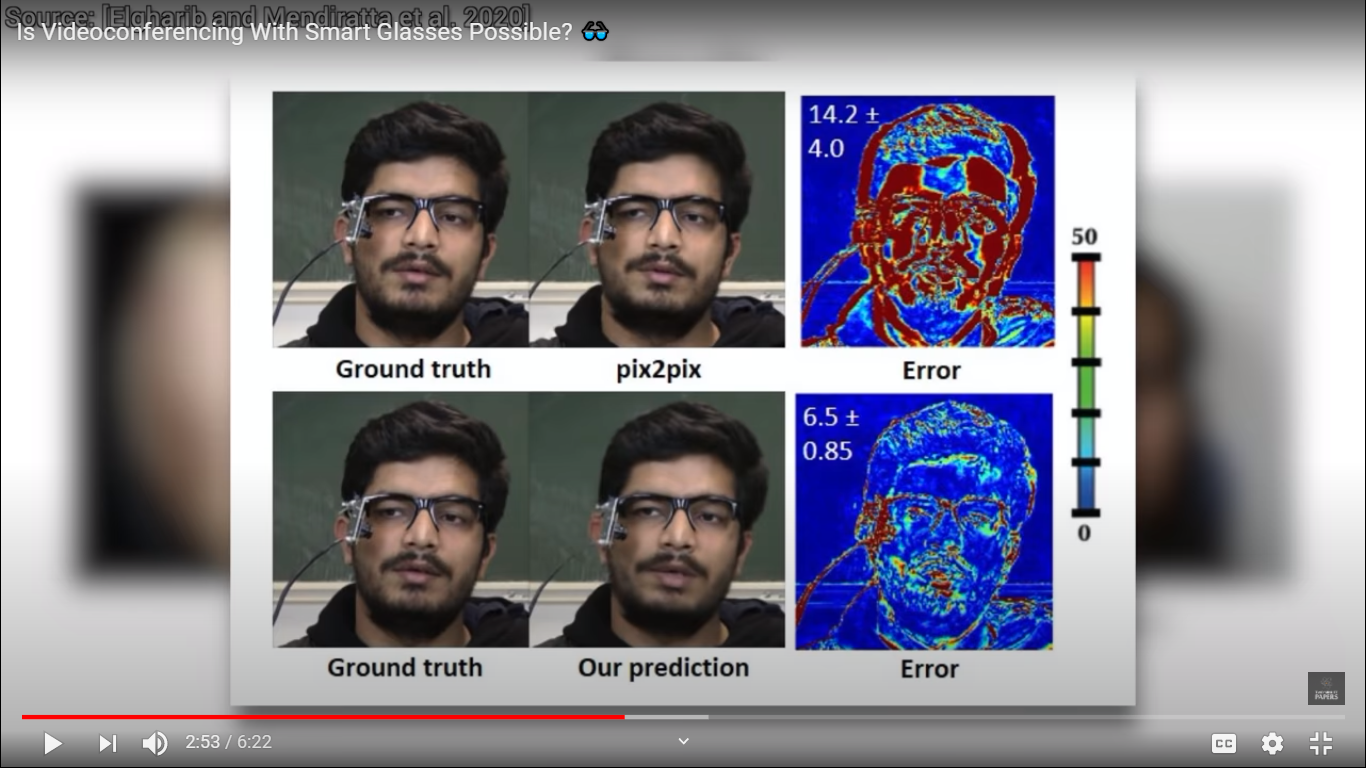
But, it is still not perfect, there are some differences. Inaccuracies can be seen using different images. In the below image the regions with warmer colors indicate where the reconstruction is inaccurate compared to the real reference footage. For instance, with an earlier method by the name pix2pix, the hair and the beard are doing fine, while there is quite a bit of reconstruction error on the remainder of the face. But this new method does much better across the entirety of the face. It still has some trouble with the cable and the glasses, but otherwise, the output is clean.
Note: This technique needs to be trained on each of the test subjects, four minutes of video footage is fine and this calibration process only needs to be done once.
So, the technique knows these people and has seen them before, and with all that extra knowledge, what else could be done with this footage? Perhaps, we can not only reconstruct but also create arbitrary head movements. Since we can guess what the real head movement is from a view of the background, we can simply remove it.

This new method isn’t perfect though. For instance, it does not work all that well in low-light situations. Still, there is a lot of promise, and research into this subject continues.
References
- Egocentric Video Conferencing: https://vcai.mpi-inf.mpg.de/projects/EgoChat/data/Main.pdf
Author
Shubham Bindal
