
Let’s talk about video super-resolution. The problem statement is simple: a coarse video goes as an input, and the technique analyzes it, guesses what’s missing, and out comes a detailed video.
When learning-based algorithms were not nearly as good as they are today, this problem was mainly handled by handcrafted techniques, but they had their limits – after all if we don’t see something too well, how could we tell what’s there? And this is where new learning-based methods, especially TecoGAN, come into play. This is a hard enough problem for even a still image, yet this technique is able to do it really well even for videos.
Let’s have a look (in the below video). The eye color for this character is blurry, but we see that it likely has a green-ish, blue-ish color. And if we gave this problem to a human, a human would know that we are talking about the eye of another human, and we know roughly what this should look like in reality.
What about computers? The key is that if we have a learning algorithm that looks at the coarse and fine version of the same video, it will hopefully learn what it takes to create a detailed video when given a poor one, which is exactly what happened here. As you see (in the below video), we can give it very little information, and it iss still able to add a stunning amount of detail to it.
The authors proposed an adversarial learning method for a recurrent training approach that supervises both spatial contents as well as temporal relationships. They applied their approach to two video-related tasks that offer substantially different challenges: video super-resolution (VSR) and unpaired video translation (UVT). With no ground truth motion available, the spatio-temporal adversarial loss and the recurrent structure enable the model to generate realistic results while keeping the generated structures coherent over time.
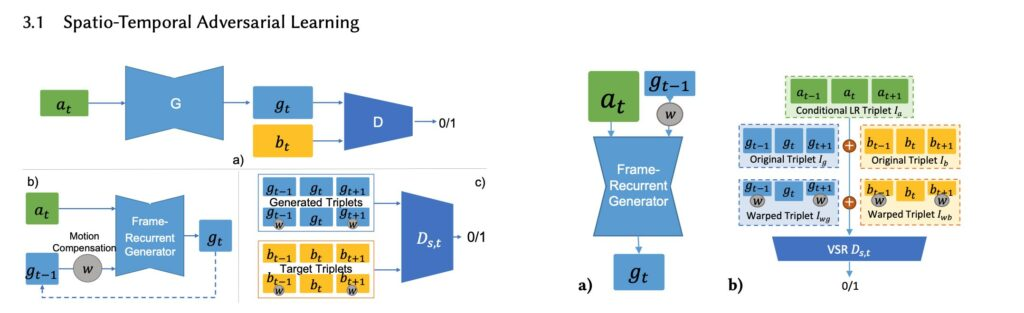
A spatio-temporal discriminator unit is used together with a careful analysis of training objectives for realistic and coherent video generation tasks, with a novel Ping Pong (PP) loss supervising long-term consistency. The PP loss effectively avoids the temporal accumulation of artifacts, which can potentially benefit a variety of recurrent architectures
Below, we are given a blocky image of this garment and its reference image that was coarsened to create this input. The reference was carefully hidden from the algorithms. Some previous works could add some details, but the results were nowhere near as good as the reference. But you can see that, for this new method TecoGAN, it is very close to the real image.
This model outperforms previous works in terms of temporally-coherent detail, which the authors have qualitatively and quantitatively demonstrated with a wide range of content.
References
Author
Shubham Bindal
